## 基本数据类型内置方法 ### 理论 基本数据一般内置的都有一定的方法可以使用 ```python 使用形式 数据值.方法 变量名.方法 ``` ### 实际操作 #### 整型 ```python int('123') # 123 #浮点型可以转,字符串内部只有纯数字才可以转。 十进制转二进制 bin(10) # 0b1010 十进制转八进制 oct(10) # 0o12 十进制转十六进制 hex(10) # 0xa 其他进制转十进制 int('1010') # 1010 int('0b1010',base=2) # 使用进制参数时要转换的必须是字符串类型,第二个参数是几进制 10 int('0o1010',base=8) # 520 int('0xa',base=16) # 10 python3本身对数字的敏感度低(精确度低) python 语言本身不厉害,厉害的是有许多大佬,开发的模块,库 如果需要精确计算需要借助与numpy····等等模块 ``` #### 浮点型 ```python float('123') # 123.0 float(10.1) # 纯数字字符串里允许出现一个小数点 python自身对数字的敏感度较低(精确度低) ``` #### 字符串 ##### 其他数据类型转字符串 ```python age = 18 name_list = ['zhang', 'zhao', 'feng', 'li'] person_dict = {'name':'zhang','age':18,'job':'student'} age = str(age) #'18' name = str(name_list) #'['zhang', 'zhao', 'feng', 'li']' person = str(persom_dict) # '{'name':'zhang','age':18,'job':'student'}' # 原理就是直接加引号 ``` ##### 统计字符串多少个字符,空格也算字符串 ```python info = 'abcdefg123' print(len(info)) # 10 ``` ##### 索引切片 ```python name = 'zhangsan' for i in name: print(i) # z h a n g s a n #一个参数索引 print(name[0]) # z #参数:5顾头不顾尾 print(name[:5]) # zhangs #但:表示全部都取顺序是从左到右 print(name[:]) # zhangsan #第三个数表示步长顺序是从左到右 print(name[::2]) # zaga #可以为负数顺序是从左到右 print(name[-1]) # n #反转字符串顺序是从左到右 print(name[-1:-5:-1]) # nasgnahz 反转字符串顺序是从右到左 ``` ##### 大小写转换与判断 ```python name = 'i LOVE you 123' #小写字母全部转换为大写,其他字符不受影响 name = name.upper() print(name) # I LOVE YOU 123 #大写字母全部转换为小写,其他字符不受影响 name = name.lower() print(name) # i love you 123 #判断字符串里面的字母是否全部为大写,如果有其他字符不影响,只判断字母 neme = 'I LOVE YOU 123' name = name.isupper() print(name) # True neme = 'I love YOU 123' name = name.isupper() print(name) # False #判断字符串里面的字母是否全部为小写,如果有其他字符不影响,只判断字母 name = 'i love you 123' name = name.isupper() print(name) # True name = 'i LOVE you 123' name = name.isupper() print(name) # False name = 'i LOVE you 123' print(name.title()) # I Love You 123 单词首字母大写 print(name.capitalize()) # I love you 123 首个单词大写其余小写 print(name.swapcase()) # I love YOU 123 大小写转换 print(name.casefold()) # i love you 123 此方法与 Lower() 方法相似,但是 casefold() 方法更强大,更具攻击性,这意味着它将更多字符转换为小写字母,并且在比较两个用 casefold() 方法转换的字符串时会找到更多匹配项。 print(name.translate()) ``` ##### 格式化字符串 ```python 方式一 info = '张三 爱 {}' print(info.format('李四')) 方式二 占位符见名知意 反复使用 info = '张三 爱 {name1} {name2} {name3}' print(info.format(name1='李四',name2='王五',name3='赵孙')) 方式三索引取值反复使用 info = '张三 爱 {0} {1} {0}' print(info.format('李四', '王五')) 方式四python官方推荐格式化反复使用 name1 = '李四' name2 = '王五' print(f'张三 爱 {name1} {name2} {name1}') ``` ##### 相加 乘 ```python info1 = '张三' info2 = '爱你' print(info1+info2) # 张三爱你 print(info2 * 3) # 爱你爱你爱你 ``` ##### 删除首尾指定字符 ```python #首尾删除 name1 = '&&张三&&' # print(name1.strip()) # 默认删除空格 print(name1.strip('&')) # 删除首尾指定字符串& 张三 #只删除左边指定字符 name1 = '&&张三&&' print(name1.lstrip('&')) # 张三&& #只删除右边指定字符 name1 = '&&张三&&' print(name1.rstrip('&')) # &&张三 ``` ##### 分割字符串 ```python #从左到右分隔 name1 = '张三 李四 王五 王婆' print(name1.split()) # 默认空格分隔 ['张三','李四','王五','王婆'] name1 = '张三|李四|王五|王婆' print(name1.split('|',maxsplit=1)) # 从左到右分隔,maxsplit最大分隔几次 ['张三','李四王五王婆'] #从右向左分隔 name1 = '张三|李四|王五|王婆' print(name1.rsplit('|',maxsplit=1)) # 从右到左分隔,maxsplit最大分隔几次 ['张三李四王五','王婆'] ``` ##### 指定字符计数 ```python counts = 'zhzhzzzdsaadad' print(counts.count('z')) # 5 print(counts.count('z',4,-1)) # 第一个是要计数的字符串,第二个是起始位置索引,第三个是结束位置索引不包含末尾 3 print(counts.count('zh')) # 2 ``` ##### 查找字符串索引 ```python find_str ="wdnmd,快滚啊" print(find_str.index('滚')) # 7 print(find_str.index('a')) # 如果查找的是字符不存在则会报错ValueError: substring not found print(find_str.rindex('滚')) # 从右边开始索引 print(find_str.find('滚')) # 7 print(find_str.find('a')) # 如果查找的是字符不存在不会报错,会返回-1再查找字符串时建议使用find查找 print(find_str.find('a',3,-1)) # 第一个是要查找的字符,第二个要查找的起始索引,第三个是末尾索引,不包含末尾 ``` ##### 替换字符串 ```python re_str = '苍老师,苍老师,叫我学习啦' print(re_str.replace('苍','张')) # 张老师,张老师,叫我学习啦 print(re_str.replace('苍','张',1)) # 张老师,苍老师,叫我学习啦 第三个参数表示,替换的次数 ``` ##### join拼接字符串 ```python name_dict = ['z','l','f','g'] print('-'.join(name_dict)) # z-l-f-g 可迭代对象数据值必须是字符串 ``` ##### 判断是否是纯数字 ```python num = '123abc' print(num.isdigit()) # False num = '①②③' # 这样判断也为True不符合我们需要的逻辑 print(num.isdigit()) #判断是否是数字是建议使用isdecimal方法 num = '123abc' print(num.isdecimal()) # True num = '①②③' # 这样判断也为False符合我们需要的逻辑 print(num.isdecimal()) # False ``` ##### 判断是否以指定字符开头或结尾 ```python info = '苍老师,波多老师,深田老师' print(info.startswith('苍老师')) # True print(info.startswith('波多老师')) # False print(info.endswith('深田老师')) # True print(info.endswith('波多老师')) # False ``` #### 列表 列表的内置操作都是直接再原列表操作的 ##### 转换列表 ```python 不是所有类型都可以转列表只能是可迭代类型的 可以被for循环的数据类型都可以转换成列表 print(list('zhang')) # ['z', 'h', 'a', 'n', 'g'] print(list((1,2,3,4,5))) # [1,2,3,4,5] print(list({1,2,3,4,5})) # [1,2,3,4,5] print(list({'name':'张三','age':18,14:'123'})) # ['name', 'age', 14] ``` ##### 索引切片 ```python num = [1,2,3,4,5] print(num[1]) # 2 print(num[0:2]) # [1,2] print(num[0::2]) # [1,3,5] print(num[-1:-5:-1]) #[5,4,3,2] num = [1,2,3,4,5] print(num.index(2)) # 1 ``` ##### 列表增加数据与数据值的修改 ```python num = [1,2,3,4,5] num[0] = 123 #数据值的修改 num.append(111) # [1,2,3,4,111] 在末尾追加数据值 num.append([111,222,333]) # [1,2,3,4,5,[111,222,333]] num.insert(0,[123,456]) # [[123,456],1,2,3,4,5] #第一参数是索引位置,第二个是数据值 可以在任意位置插入数据值 ``` ##### 列表之间的合并 ```python li1 = [1,2,3,4] li2 = [111,222,333,444] li3 = li1+li2 print(li3) # [1, 2, 3, 4, 111, 222, 333, 444] li1.extend(li2) print(li1)[1, 2, 3, 4, 111, 222, 333, 444] ``` ##### 列表元素的删除 ```python li1 = ['z','h',1,3,'a'] del li1[0] # 通用删除关键字del print(li1) # ['h', 1, 3, 'a'] li1 = ['z','h',1,3,'a'] li1.remove('z') # ['h', 1, 3, 'a'] li1.remove('c') # 移除的元素不存在则会报错 ValueError: list.remove(x): x not in list li1 = ['z','h',1,3,'a'] li1.pop(0) # 参数为索引值 ['h', 1, 3, 'a'] num = li1.pop(0) # num为pop删除的数据值 li1.pop() # ['z','h',1,3] 没有参数时默认删除末尾数据值 ``` ##### 列表统计指定字符出现的次数 ```python li1 = [1,1,1,222,3,1,1,2,3] print(li1.count(1)) # 5 ``` ##### 列表的排序与颠倒列表 ```python li1 = [1,2,3,6,4,5,9] li1.sort() # [1, 2, 3, 4, 5, 6, 9] 升序排序 li1.sort(reverse=True) # [9, 6, 5, 4, 3, 2, 1] 降序排序 li1.reverse() # [9, 5, 4, 6, 3, 2, 1] 反向列表 ``` #### 字典 ##### 按key取值 ```python dict数据类型转换 dict([('name','张三'),('age',18)]) info = { 'name':'zhang', 'age':18, 'gender':'男' } print(info['name']) # 张三 ``` ##### 字典添加 ```python info['salary'] = 188 # 没有数据值直接添加 info['age'] = 19 # 有数据则修改 info['add'] = ['北京'] # 可添加任意数据值 ``` ##### 字典的删除 ```python del info['age'] info.pop() # 按key删除 info.popitem() # 随机删除一个键值对 ``` ##### 字典三剑客 ```python info.keys() # 获取字典全部键 info.values() # 获取所有值 info.items() # 获取所有键值对,以列表形式返回,但不能索引 ``` ##### 其他一些了解即可方法 ```python info.update([('name','张三'),('age',18)]) # 没有则增加 有则覆盖 info.setdefault('name','默认数值') # 键不在字典插入默认值,再字典返回key的值 info = info.fromkeys(('name', 'age', 'gender'),[]) # 需要接收返回的字典 如果值是可变类型,再操作不同key的时候值由于内存地址一样会导致,数据混乱,所以再使用时要从新赋值使用 len(info) # 统计键值对个数 ``` #### 元组 取值 ```python 数据类型转换 tuple([1,2,3,4,5]) ts = (1,2,3,4,5,2) 索引取值 ts[0] 切片 ts[0:3] ts.index(2) # 1 查找指定数据的第一次出现的下标 ts.count(2) # 2 查找指定字符再元组中出现的次数 len() # 统计元素值 ``` #### 集合 ```python 集合是无序的 一般只用于 1.去重 2.关系运算 其他情况不建议考虑 数据类型转换set()自能转换不可变类型数据 a = set([(123, 3123), (123, 1231)]) print(a) # {(123, 3123), (123, 1231)} len(a) # 统计元素个数 a.remove('数据值') # 删除数据值 不存在报错 KeyError: 'asdasd' a.add('数据值') # 添加数据值 ``` ##### 集合关系运算 ```python s1 = {'张三','李四','王五','媒婆'} s2 = {'张三','媒婆','西施','武大郎'} s1 & s2 # 交集 {'张三', '媒婆'} s1 | s2 # 并集 {'张三', '西施', '武大郎', '媒婆', '王五', '李四'}自动去重 s1 ^ s2 # 差集 {'武大郎', '西施', '王五', '李四'} s1 = {1, 2, 3, 4} s2 = {1, 2, 3} #父集 子集 s1 > s2 # 父集包含子集 True s1 < s2 # 子集包含父集 False ``` ## 字符编码 ### 理论 ```python 该知识点理论特别多 但是结论很少 代码使用也很短 1.字符编码只针对文本数据 2.计算机内部存储数据的本身是一大堆二进制数据 3.机然计算机内部只认数二进制 为什么我们却可以打出人类各式各样的字符 肯定存在一个数字跟字符的对应关系存储该关系的地方成为-->:字符编码本 4.字符编码发展史 1.一家独大 计算机是由美国人发明的为了能够让计算机识别英文 需要发明一个数字跟英文字母的对应关系 ASCII码:记录了英文字母跟数字的对应关系 用8bit(1字节)来表示一个英文字符 2.群雄割据 中国 GBK码:记录了英文、中文与数字的对应关系 用至少16bit(2字节)来表示一个中文字符 很多生僻字还需要使用更多的字节 英文还是用8bit(1字节)来表示 日本 shift_JIS码:记录了英文、日文与数字的对应关系 韩国人 Euc_kr码:记录了英文、韩文与数字的对应关系 """ 每个国家的计算机使用的都是自己制定的编码本 不同国家的文本数据无法直接交互 会出现'乱码' """ 3.编码统一 unicode万国码 兼容所有国家的语言字符 起步就是两个字节来表示字符 utf系列:utf8 utf16 ··· 专门用于优化unicode存储问题 英文还是采用一个字节(8bit) 中文由于中国文化博大精深需要采用三个字节 ``` 实操 ```python 1.针对乱码不要慌 切换编码慢慢试即可 2.编码与解码 编码:能将人类的字符按照指定的编码编码成计算机能读得懂的数据(二进制0010) 字符串.encode('utf-8') #以utf-8节码 节码:将计算机能够读懂的数据按照指定的便阿门解码成人能够读懂的数据 bytes类型数据.decode('utf-8') # 以utf-8解码 3.python2与python3差异 python2默认的编码啊ASCII 1.文件头 #-*- encoding:utf-8 -*-#-*-就是美观而已,其他没什么作用 2.字符串前面加u u'你好啊' python3默认的编码是utf系列(unicode) name = 'zhangsan啊' name.encode('utf-8') # b'zhangsan\xe5\x95\x8a' name = name.encode('utf-8') print(name.decode('utf-8')) #zhangsan啊 ``` ## 可变与不可变 ### 可变类型(数据值改变,内存地址不变) 列表,集合,字典在调用内置方法后是修改自己,并没有产生一个新的结果 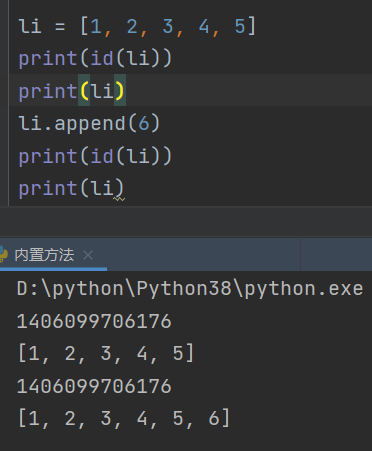 ### 不可变类型(数据值改变,内存地址立即改变)(可哈希) 整型,浮点型,字符串,元组,布尔True哈希为1False哈希为0 字符串在调用内部方法后并不会修改自己而是产生一个新的字符串,需要用一个变量名去接收 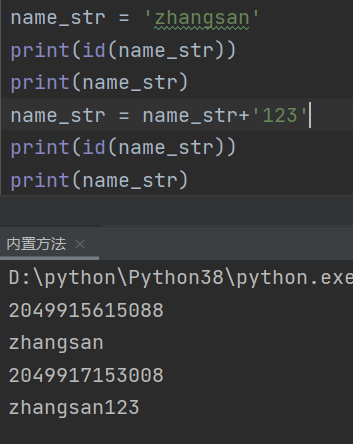 ## 作业练习1 ```python ''' 1.基于字符串充当数据库完成用户登录(基础练习) data_source = 'jason|123' # 一个用户数据 获取用户用户名和密码 将上述数据拆分校验用户信息是否正确 ''' # 1.分隔数据 data_source = 'jason|123' # 2.解压接收数据 name, pwd = data_source.split('|') # 3.实现错误可以重新输入 while True: # 4.获取用户输入用户名或密码,删除首尾空格 user_name = input('请输入用户名').strip() pass_word = input('请输入密码').strip() # 5.判断用户名密码是否正确 if user_name == name and pass_word == pwd: print('登录成功') # 登录成功直接结束 break print('用户名或密码错误,请重新登录') ``` ```python ''' 2.基于列表充当数据库完成用户登录(拔高练习) # 多个用户数据 data_source = ['jason|123', 'kevin|321','oscar|222'] ''' # 1.用户列表接收 data_source = ['jason|123', 'kevin|321', 'oscar|222'] # 2.实现错误可以重新输入 # 7.全局标识符,方便统筹管理 flag = True while flag: # 3.获取用户输入用户名和密码,删除首尾空格 user_name = input('请输入用户名').strip() pass_word = input('请输入密码').strip() # 4.循环比对用户列表数据 for user_data in data_source: # 5.解压接收数据 name, pwd = user_data.split('|') # 6.判断用户名密码 if user_name == name and pass_word == pwd: print('登录成功') flag = False break else: print('用户名或密码不正确,请重新输入') ``` ```python ''' 3.利用列表编写一个员工姓名管理系统 输入1执行添加用户名功能 输入2执行查看所有用户名功能 输入3执行删除指定用户名功能 """分析 用户输入的不同 可以执行不同的代码""" ps: 思考如何让程序循环起来并且可以根据不同指令执行不同操作 提示: 循环结构 + 分支结构 拔高: 是否可以换成字典或者数据的嵌套使用完成更加完善的员工管理而不是简简单单的一个用户名(能写就写不会没有关系) ''' # 1.创建一个用户信息字典 user_info = {'zhangsan': {'user_name': 'zhangsan', 'name': '张三', 'pass_word': '123', 'user_phone_number': '123123', 'user_addr': '北京' }, 'jasonji': {'user_name': 'jasonji', 'name': 'jason', 'pass_word': '12345', 'user_phone_number': '11122333', 'user_addr': '上海' } } sys_func = ['1.用户登录', '2.添加用户信息', '3.查看所有用户名信息', '4.删除指定用户名', '5.退出登录'] # 循环输入使用 sys_admin = ['zhangsan', '李四'] print('用户管理系统'.center(20)) is_login = None try: while True: for k in sys_func: print(k) num = input('请输入功能编号 退出(q/Q)').strip() if num.upper() == 'Q': break if not num.isdecimal(): print('请输入数字') continue num = int(num) if num == 1: print(sys_func[num - 1]) if is_login: print('您已经登录过了') continue user_name = input('请输入用户名 退出(q/Q)').strip() if user_name.upper() == 'Q': continue pass_word = input('请输入密码').strip() for k, v in user_info.items(): # 遍历用户信息字典 if user_name == v['user_name'] and pass_word == v['pass_word']: # 比对用户名密码 print('登录成功') is_login = user_name # 登录状态设置 break else: print('登录失败请检查用户名或密码') elif num == 2: print(sys_func[num - 1]) user_name = input('请输入用户名 退出(q/Q)').strip() if user_name.upper() == 'Q': continue name = input('请输入姓名').strip() while True: # 重复输入 pass_word = input('请输入密码').strip() pass_checked = input('请再次输入密码').strip() if not pass_word == pass_checked: # 判断两次密码输入是否正确 print('两次输入密码不同信息请重新输入') else: break user_phone_number = input('请输入用户手机号').strip() user_addr = input('请输入用户家庭地址').strip() if user_name in user_info: print('用户名已存在,请重新输入') continue # 添加用户信息 user_info[user_name] = {'user_name': user_name, 'name': name, 'pass_word': pass_word, 'user_phone_number': user_phone_number, 'user_addr': user_addr } print('用户信息添加成功') elif num == 3: print(sys_func[num - 1]) if not is_login: # 检查是否登录 print('你还没有登录请登录') continue if is_login not in sys_admin: # 检查是否管理员 print('您不是管理员没有权限查看用户信息') continue for k, v in user_info.items(): # 遍历用户信息字典 print( f"姓名:{v['name']},用户名:{v['user_name']},密码:{v['pass_word']},手机号:{v['user_phone_number']},家庭住址:{v['user_addr']}") elif num == 4: print(sys_func[num - 1]) if not is_login: print('你还没有登录请登录') continue if is_login not in sys_admin: print('您不是管理员没有权限删除用户信息') continue while True: user_name = input('请输入用户名 退出(q/Q)').strip() if user_name.upper() == 'Q': break if user_name not in user_info: # 检查用户是否存在 print('用户不存在,请检查用户名') continue del user_info[user_name] print(f'{user_name}用户删除成功') break elif num == 5: print(sys_func[num - 1]) if not is_login: print('你还没有登录无需退出') continue is_login = None print('退出成功') else: print('输入有误请重新输入') continue except Exception as e: print(e) ``` ## 作业练习2 ```python ''' 1.优化员工管理系统 拔高: 是否可以换成字典或者数据的嵌套 使用完成更加完善的员工管理而不是简简单单的一个用户名(能写就写不会没有关系) ''' # 1.创建一个用户信息字典 user_info = {'zhangsan': {'user_name': 'zhangsan', 'name': '张三', 'pass_word': '123', 'user_phone_number': '123123', 'user_addr': '北京' }, 'jasonji': {'user_name': 'jasonji', 'name': 'jason', 'pass_word': '12345', 'user_phone_number': '11122333', 'user_addr': '上海' } } sys_func = ['1.用户登录', '2.添加用户信息', '3.查看所有用户名信息', '4.删除指定用户名', '5.用户信息修改', '6.退出登录'] # 循环输入使用 sys_admin = ['zhangsan', '李四'] print('用户管理系统'.center(20)) is_login = None try: while True: for k in sys_func: print(k) num = input('请输入功能编号 退出(q/Q)').strip() if num.upper() == 'Q': break if not num.isdecimal(): print('请输入数字') continue num = int(num) if num == 1: print(sys_func[num - 1]) if is_login: print('您已经登录过了') continue user_name = input('请输入用户名 退出(q/Q)').strip() if user_name.upper() == 'Q': continue pass_word = input('请输入密码').strip() for k, v in user_info.items(): # 遍历用户信息字典 if user_name == v['user_name'] and pass_word == v['pass_word']: # 比对用户名密码 print('登录成功') is_login = user_name # 登录状态设置 break else: print('登录失败请检查用户名或密码') elif num == 2: print(sys_func[num - 1]) user_name = input('请输入用户名 退出(q/Q)').strip() if user_name.upper() == 'Q': continue name = input('请输入姓名').strip() while True: # 重复输入 pass_word = input('请输入密码').strip() pass_checked = input('请再次输入密码').strip() if not pass_word == pass_checked: # 判断两次密码输入是否正确 print('两次输入密码不同信息请重新输入') else: break user_phone_number = input('请输入用户手机号').strip() user_addr = input('请输入用户家庭地址').strip() if user_name in user_info: print('用户名已存在,请重新输入') continue # 添加用户信息 user_info[user_name] = {'user_name': user_name, 'name': name, 'pass_word': pass_word, 'user_phone_number': user_phone_number, 'user_addr': user_addr } print('用户信息添加成功') elif num == 3: print(sys_func[num - 1]) if not is_login: # 检查是否登录 print('你还没有登录请登录') continue if is_login not in sys_admin: # 检查是否管理员 v = user_info[is_login] print('您不管理员只能查看自己的信息') print(f"姓名:{v['name']},用户名:{v['user_name']},密码:{v['pass_word']},手机号:{v['user_phone_number']},家庭住址:{v['user_addr']}") continue for k, v in user_info.items(): # 遍历用户信息字典 print( f"姓名:{v['name']},用户名:{v['user_name']},密码:{v['pass_word']},手机号:{v['user_phone_number']},家庭住址:{v['user_addr']}") elif num == 4: print(sys_func[num - 1]) if not is_login: print('你还没有登录请登录') continue if is_login not in sys_admin: print('您不是管理员没有权限删除用户信息') continue while True: user_name = input('请输入用户名 退出(q/Q)').strip() if user_name.upper() == 'Q': break if user_name not in user_info: # 检查用户是否存在 print('用户不存在,请检查用户名') continue del user_info[user_name] print(f'{user_name}用户删除成功') break elif num == 5: print(sys_func[num - 1]) if not is_login: print('你还没有登录请登录') continue while True: user_name = input('请输入用户名 退出(q/Q)').strip() if user_name.upper() == 'Q': break if user_name not in user_info: # 检查用户是否存在 print('用户不存在,请检查用户名') continue if is_login not in sys_admin: if user_name != is_login: print('没有权限修改其他人信息') continue else: user_name = input('请输入用户名 退出(q/Q)').strip() if user_name.upper() == 'Q': break name = input('请输入姓名').strip() while True: # 重复输入 pass_word = input('请输入密码').strip() pass_checked = input('请再次输入密码').strip() if not pass_word == pass_checked: # 判断两次密码输入是否正确 print('两次输入密码不同信息请重新输入') else: break user_phone_number = input('请输入用户手机号').strip() user_addr = input('请输入用户家庭地址').strip() user_info[user_name].update({'user_name': user_name, 'name': name, 'pass_word': pass_word, 'user_phone_number': user_phone_number, 'user_addr': user_addr }) print(f'{user_name}信息修改成功') break elif num == 6: print(sys_func[num - 1]) if not is_login: print('你还没有登录无需退出') continue is_login = None print('退出成功') else: print('输入有误请重新输入') continue except Exception as e: print(e) ``` ``` """ 2.去重下列列表并保留数据值原来的顺序 eg: [1,2,3,2,1] 去重之后 [1,2,3] l1 = [2,3,2,1,2,3,2,3,4,3,4,3,2,3,5,6,5] """ l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5] li_list = [] for i in l1: if i not in li_list: li_list.append(i) l1 = li_list print(l1) ``` ``` """ 3.有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合 pythons={'jason','oscar','kevin','ricky','gangdan','biubiu'} linuxs={'kermit','tony','gangdan'} 1. 求出即报名python又报名linux课程的学员名字集合 2. 求出所有报名的学生名字集合 3. 求出只报名python课程的学员名字 4. 求出没有同时这两门课程的学员名字集合 """ pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'} linuxs = {'kermit', 'tony', 'gangdan'} # 1. print(pythons & linuxs) # 2. print(pythons | linuxs) # 3. print(pythons & linuxs ^ pythons) #首先去交集,然后排除交集里面的名字就是单独python里的 # 4. print(pythons ^ linuxs) ``` ``` """ 4.统计列表中每个数据值出现的次数并组织成字典战士 eg: l1 = ['jason','jason','kevin','oscar'] 结果:{'jason':2,'kevin':1,'oscar':1} 真实数据 l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin'] """ l1 = ['jason', 'jason', 'kevin', 'oscar', 'kevin', 'tony', 'kevin'] l1_dict = {} for name in set(l1): # 去重后遍历 l1_dict[name] = l1.count(name) # 列表count计数 print(l1_dict) ``` Last modification:October 2nd, 2022 at 12:08 am © 允许规范转载 Support 如果觉得我的文章对你有用,请随意赞赏 ×Close Appreciate the author Sweeping payments
Comment here is closed